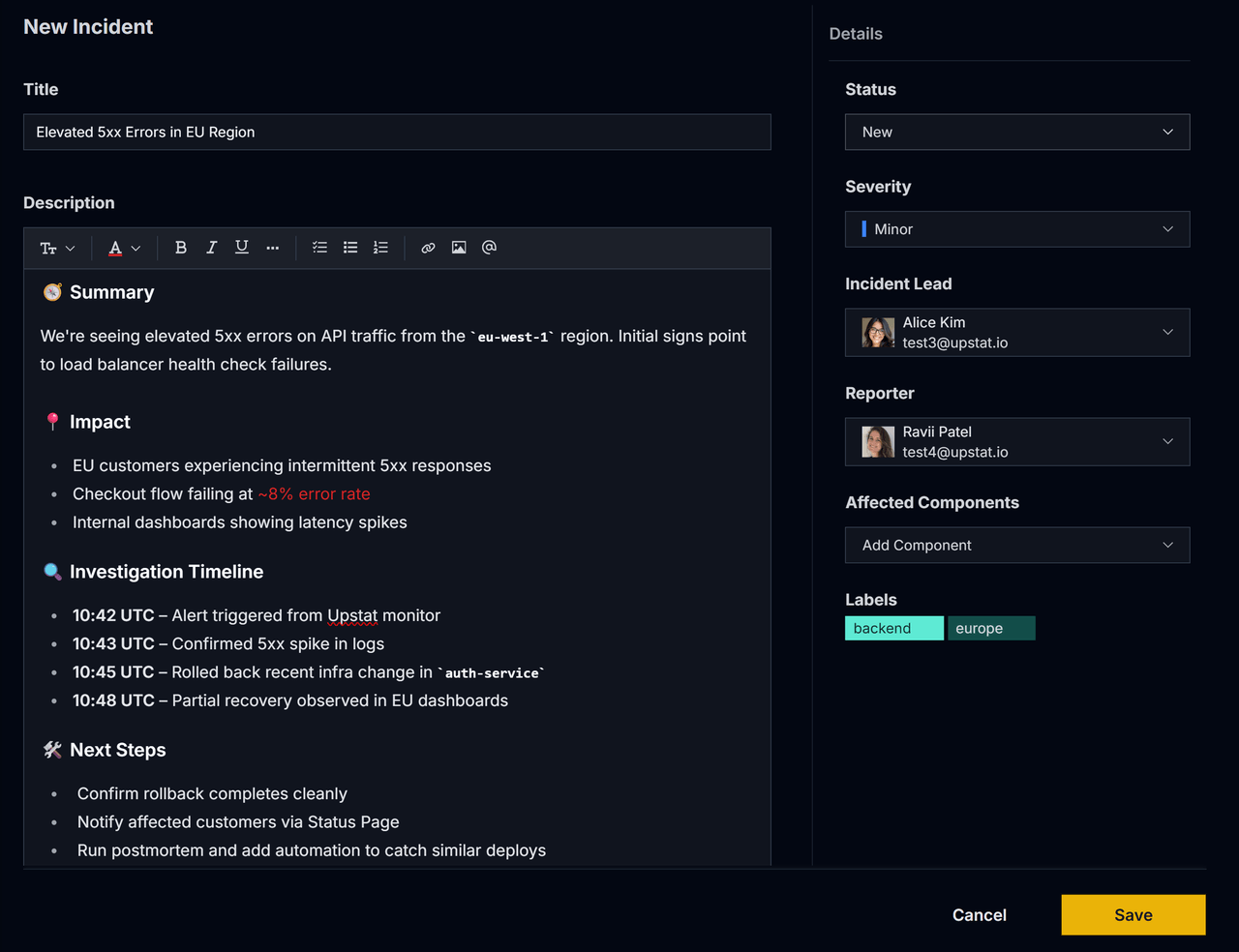
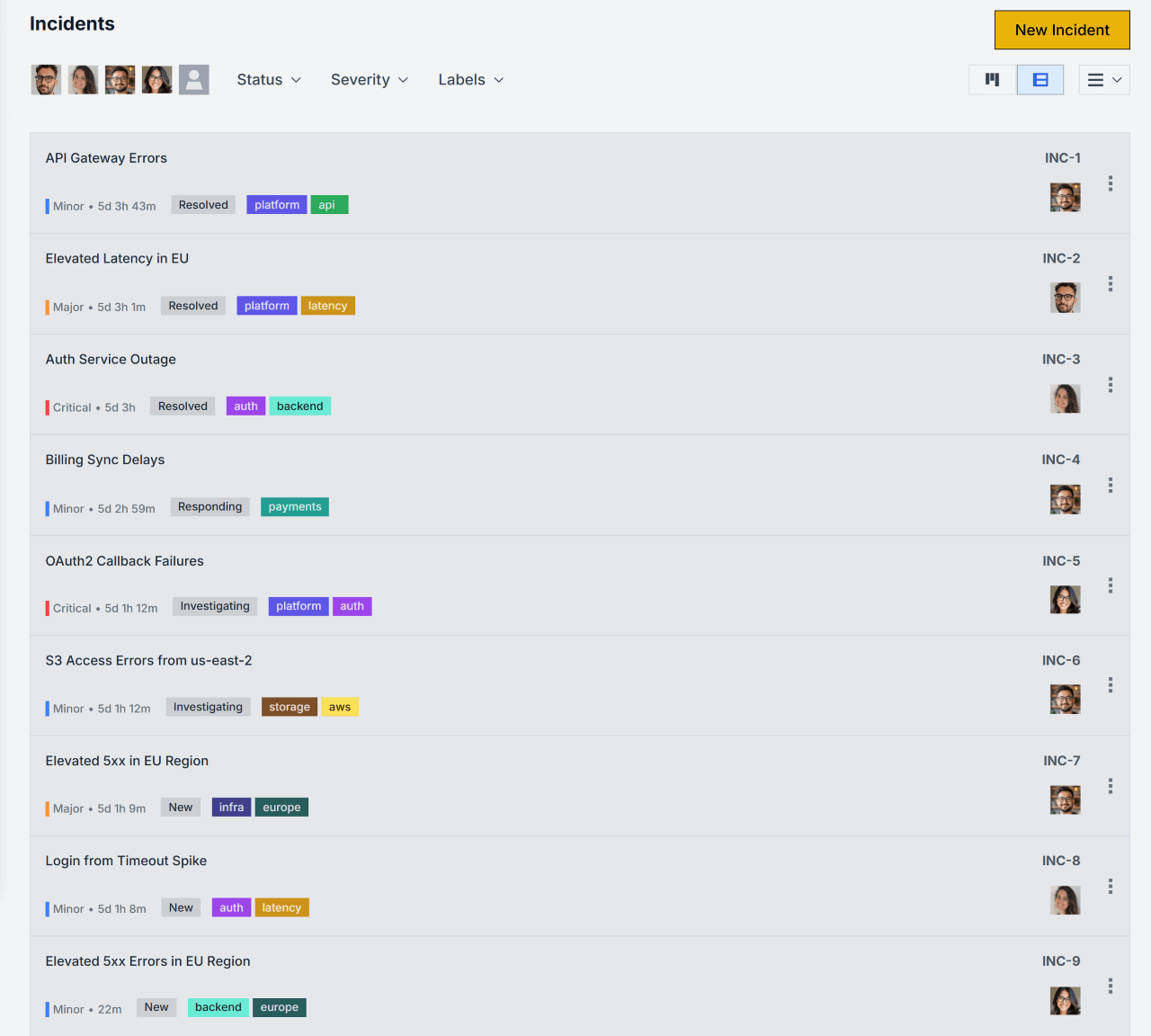
Capture every detail—without slowing down.
Upstat’s rich-text editor makes it easy to log structured, high-context incidents using Markdown. Add timelines, tag teammates, format impact summaries, and embed key links—all without switching tools or losing clarity.
Declare incidents with the precision your team needs—whether it's SEV-1 or a customer-facing bug.
- Markdown-Powered Editor
Format timelines, impact sections, and next steps with intuitive formatting.
- Structured Yet Flexible
Add status, severity, reporter, lead, and affected systems with just a few clicks.
- Context-Rich Collaboration
Mention teammates, attach files, and keep everything in one place.
- Fast Entry When Time Matters
Create and submit incidents in seconds—without sacrificing clarity.