How to transfer on-call responsibility smoothly without losing context or dropping critical information.
Why the same incident update can help your team while confusing customers—and how to communicate effectively to both audiences.
How to build fair, sustainable on-call rotations that maintain coverage without burning out your team.
Practical strategies that help teams resolve incidents faster through better detection, coordination, and structured response.
The difference between chaos and coordinated response comes down to how you communicate when systems fail.
Learn how to classify incidents effectively and build a severity framework that helps teams respond faster.
The single point of accountability for incident response, from detection to resolution.
A practical guide to recognizing operational toil and reducing it through automation, measurement, and engineering work.
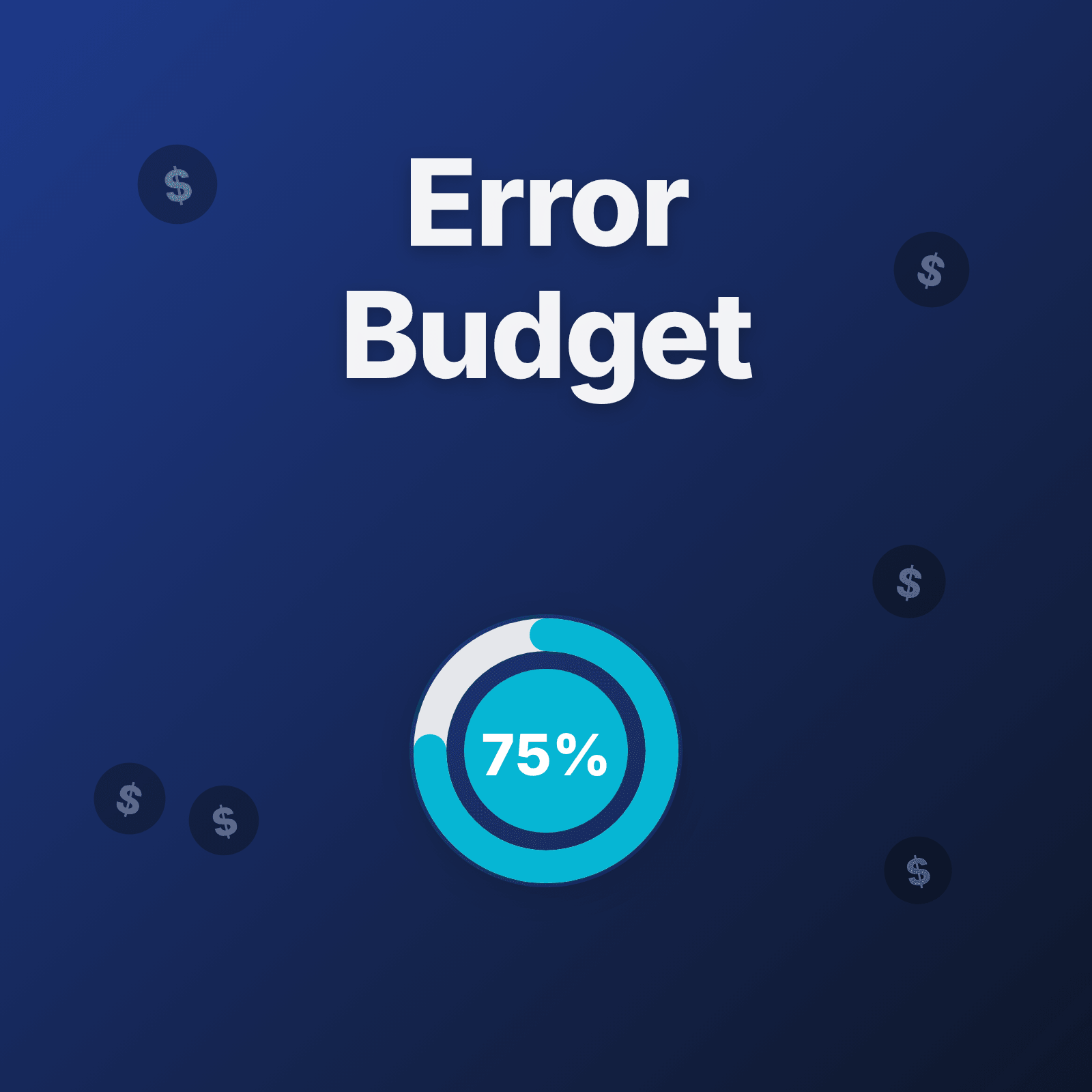
The reliability concept that tells teams when to ship fast and when to slow down—backed by data, not politics.